
티스토리 뷰
집계 함수
-데이터 베이스 시스템은 총 다섯개의 집계함수를 지원하는데 종류는 아래와 같습니다.(윈도우 함수에 포함됨)
해당 집계함수들은 여러 행의 값을 집계하여 특정 작업을 거쳐 단일 값을 반환합니다.
해당 집계함수는 중복제거를 해주지 않으며,중복제거를 하려면 값 앞에 distinct를 붙여야합니다.
ex) SELECT count(distinct name) FROM database;
- avg(값) : 평균값 구하는 함수
- min(값): 최소값 구하는 함수
- max(값): 최대값 구하는 함수
- sum(값) : 값의 총합 구하는 함수
- count(값) : 갑의 개수를 계산하는 함수
COUNT(*)는 NULL값을 포함합니다.
COUNT(표현식)은 NULL값을 포함하지않습니다.
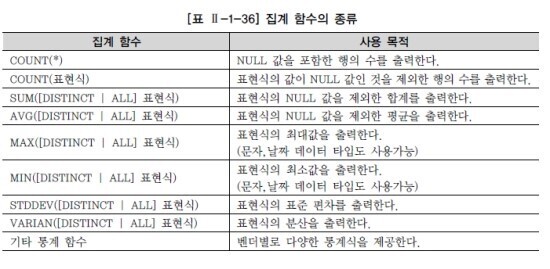
null값과 집계함수
-집계함수는 기본적으로 널값 무시하며, count는 널값을 세지않고, 그외함수들은 null을 반환합니다.
count(null) = 0
max(null) = null
max(null) = null
그룹함수
-고급 그룹화 연산을 제공하는 함수로, 간단한 집계연산이아닌 복잡한 집계쿼리를 작성할때 편리함을 제공하는 함수입니다.
GROUP BY연산이 필수로 들어가며 계층적 집계를 구현할 수 있습니다.
- ROLLUP 함수
-지정된 열 순서에 따라 계층적으로 그룹화를 수행하는 함수입니다.
-기본적으로 열리스트에서 왼쪽에서 오른쪽으로 그룹화를 수행하며, 각 단계에서 이전 열을 포함한 집계를 추가로 생성합니다.

위와 같은 테이블이 있고, 아래와 같은 SQL 문을 실행한다 했을때,
SELECT department_id, job_id, SUM(salary)
FROM employees
GROUP BY ROLLUP(department_id, job_id);
아래와 같은 결과를 나타냅니다.
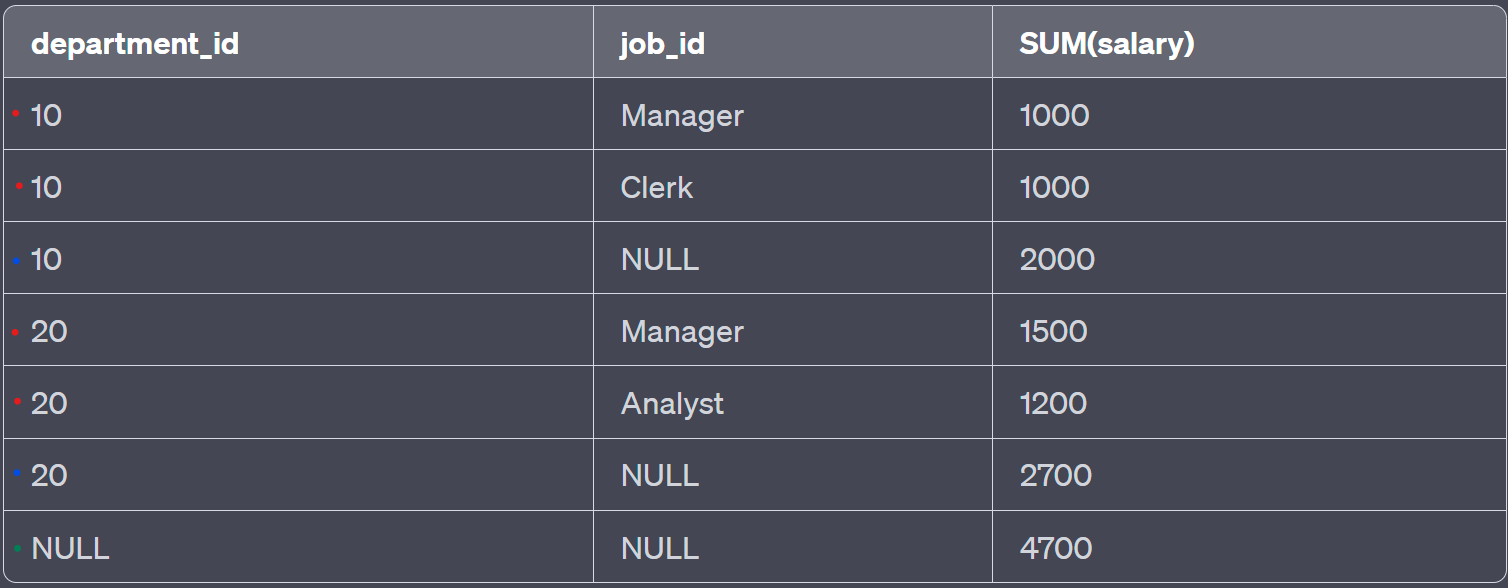
빨간색은 그룹(2개)별 합계, 파랑색은 상위 그룹(1개) 전체 합계 , 초록색은 전체 합계입니다.
이런 식으로 ROLLUP 함수는 각 GROUP BY의 그룹별 결과를 계층적으로 올라가면서 나타낼 수 있습니다.
- CUBE 함수
-주어진 모든 열의 조합에 대한 집계생성하는 함수입니다.
-여러 차원의 모든 가능한 조합에 대해 그룹화를 수행하며, ROLLUP보다 더 많은 집합을 구합니다.

위와 같은 테이블이 있고, 아래와 같은 SQL 문을 실행한다 했을때,
SELECT department_id, job_id, SUM(salary)
FROM employees
GROUP BY CUBE(department_id, job_id);
아래와 같은 결과를 나타냅니다.

빨간색은 그룹(2개)별 합계, 파랑색은 상위 그룹(1개) 전체 합계 , 초록색은 전체 합계입니다.
ROLLUP은 상위 그룹이 계층적으로 되어있어, 한개의 상위 그룹씩 올라갔지만, CUBE는 가능한 모든값에 대해서
다 구한 다는 차이점이 있습니다. 파랑색 부분을 보시면 department_id그룹 말고도 job_id 부분도 합계부분이 추가된걸 볼 수 있습니다.
- GROUPING SETS 함수
-주어진 모든 열의 조합에 대한 집계생성하는 함수입니다.
-이는 사용자가 원하는 특정 그룹화 조합을 지정하여 집계를 수행합니다.
-이를 통해 사용자는 모든 그룹화 수준의 집계를 한번의 쿼리로 원할 수 있습니다.

위와 같은 테이블이 있고, 아래와 같은 SQL 문을 실행한다 했을때,
SELECT department_id, job_id, SUM(salary)
FROM employees
GROUP BY GROUPING SETS((department_id, job_id), (department_id), (job_id), ()); //사용자 정의 집합
아래와 같은 결과를 나타냅니다.

빨간색은 그룹(2개)별 합계, 파랑색은 상위 그룹(1개) 전체 합계 , 초록색은 전체 합계입니다.
GROUPING SETS는 이런식으로 쿼리에 사용자가 원하는 집합을 직접 입력함으로써 원하는 집합의 집계만 한번에 뽑아서 볼 수 있습니다.
윈도우함수(Window Function)란?
-윈도우 함수란 행과 행 간을 쉽게 비교,연산,정의하기 위한 함수입니다.
주로 분석, 순위를 정하는데에 사용되며, OVER문구가 필수적으로 들어가야 한다는 특징이 있습니다.
| 함수 구분 | 함수 종류 | 설명 |
| 순위 함수 | RANK , DENSE_RANK , ROW_NUMBER | 각 행의 순위를 보여주는 함수 |
| 집계 함수 | SUM , MAX , MIN, AVG , COUNT | 특정 레코드를 골라 집계를 내는 함수 |
| 순서 함수 | FIRST_VALUE , LAST_VALUE , LAG , LEAD | 레코드들의 순서를 나타내는 함수 |
| 비율 함수 | CUME_DIST , PERCENT_RANK , RATIO_TO_REPORT , NTILE | 레코드들의 비율을 나타내는 함수 |
윈도우 함수의 기본 사용법
SELECT WINDOW_FUNCTION (ARGUMENTS)
OVER ( [PARTITION BY 칼럼] [ORDER BY 절] [WINDOWING 절] ) FROM 테이블 명;
순위함수
- RANK()
-특정 속성을 순위를 매겨 정렬해주는 함수(동일한 값에는 동일한 순위가 부여되며, 그 다음순위는 "건너뛰기"가 됩니다.)
SELECT name,RANK() over (ORDER BY height desc) as hRank FROM student;
->학생 테이블에서 키를 기반으로 내림차순으로 정렬하는 명령. (속성은 name, rank라는 등수가 출력됨)
->널값이 포함될 시, 기본(ASC)에는 널값을 가장크게, DESC에는 널값을 가장 작게봄.
- DENS_RANK()
-특정 속성을 순위를 매겨 정렬해주는 함수(동일한 값에는 동일한 순위가 부여되나, 그 다음 순서는 "건너뛰기"가 없이 바로 뒷숫자로 부여됩니다.
SELECT name,DENSE_RANK() over (ORDER BY height desc) as hRank FROM student;
->학생 테이블에서 키를 기반으로 내림차순으로 정렬하는 명령. (속성은 name, rank라는 등수가 출력됨)
->널값이 포함될 시, 기본(ASC)에는 널값을 가장크게, DESC에는 널값을 가장 작게봄.
- ROW_NUMBER()
-결과 집합의 각 레코드에 고유한 순차적 번호를 할당합니다.(동일한 값이 여러 행이 있더라도 고유한 번호가 할당됩니다.)
SELECT name, ROW_NUMBER() OVER (ORDER BY height DESC) as hRank FROM student;
->학생 테이블에서 키를 기반으로 고유한 번호를 할당하는 명령
->널값이 포함될 시 , 널 값에도 고유한 번호가 할당되며, 널값의 정렬은 DBMS마다 다릅니다.
집계함수
-앞에 설명했던 집계함수와 같습니다.
순서 함수
- FIRST_VALUE()
-지정된 윈도우(속성) 내에서 첫번째 값을 반환합니다.
SELECT date, sales,
FIRST_VALUE(sales) OVER (ORDER BY date) as first_sale_value
FROM sales_data;
- LAST_VALUE()
-지정된 윈도우(속성) 내에서 마지막 값을 반환합니다.
SELECT date, sales,
LAST_VALUE(sales) OVER (ORDER BY date ) as last_sale_value
FROM sales_data;
- LAG()
-현재 행 기준으로 지정된 거리만큼 떨어진 이전의 행 값을 반환합니다.
SELECT date, sales,
LAG(sales, 1) OVER (ORDER BY date) as prev_day_sales
FROM sales_data;
- LEAD()
-현재 행 기준으로 지정된 거리만큼 떨어진 다음의 행 값을 반환합니다.
SELECT date, sales,
LEAD(sales, 1) OVER (ORDER BY date) as next_day_sales
FROM sales_data;
비율 함수
- CUME_DIST()
-현재 행의 누적 분포를 계산합니다.
현재 행의 값이 전체 데이터 분포에서 어디에 위치하는지를 나타내는 백분위의 값이 결과 값입니다.
결과는 0과1사이의 값으로, 현재 행의 상대적인 위치를 나타냅니다.
SELECT score, CUME_DIST() OVER (ORDER BY score) as percentile_rank
FROM student_scores;
- PERCENT_RANK()
-현재 행의 백분위 순위를 계산합니다.
CUME_DIST() - 1/N의 결과와 동일합니다. (여기서 N은 전체 행 수 입니다.)
SELECT score, PERCENT_RANK() OVER (ORDER BY score) as percent_rank
FROM student_scores;
- RATIO_TO_REPORT()
-현재 행의 값이 전체 합계에 대해 차지하는 비율을 계산합니다.
SELECT product, sales,
RATIO_TO_REPORT(sales) OVER () as sales_ratio
FROM product_sales;
- NTILE(N)
-결과 집합을 N개의 동일한 부분으로 분할하고, 각행이 어느 부분에 속하는지를 나타내는 숫자를 반환합니다.
SELECT score, NTILE(4) OVER (ORDER BY score) as quartile
FROM student_scores;
'DB' 카테고리의 다른 글
| 인덱스(Index) (0) | 2023.08.14 |
|---|---|
| 옵티마이저(Optimizer) (0) | 2023.08.14 |
| SQL 서브쿼리 (0) | 2023.08.11 |
| SQL 집합 연산 (0) | 2023.08.11 |
| SQL 조인 (0) | 2023.08.11 |
- Total
- Today
- Yesterday
- 배포
- 프로토콜
- 메세지큐
- 파인튜닝
- 자동화
- 컴퓨터구조
- 문법
- JPA
- 서버
- 네트워크
- 데이터
- 포트포워딩
- 웹소켓
- IP주소
- sql
- 테이블
- 쿼리
- 스프링
- 클라우드
- 깃허브
- nat
- 소프트웨어공학
- DB
- 컨테이너
- 도커
- 자바
- 보안
- 데이터베이스
- 인공지능
- 깃
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |