
티스토리 뷰
SQL(Strictured Query Language)이란?
-데이터베이스 관리 시스템(DBMS)에서 데이터를 관리하기 위해 사용되는 프로그래밍 언어 입니다.ANSI(미국 국가표준 협회)에서 표준화 되어, 대부분의 데이터베이스 관리 시스템에서 사용됩니다. 주로 관계형 데이터베이스에서 사용되며 테이블간 관계설정, 조인을 수행해 데이터를 조작할 수 있습니다.
SQL 명령어
DDL(Data Definition Language) - 데이터 정의 언어
- 데이터베이스를 구성하는 스키마와 같은 구조적 요소를 정의하고 관리하는 언어
- 데이터베이스 객체 (스키마) 들을 생성,수정,삭제하는 명령어 포함함
- DDL 실행 효과는 데이터 사전에 반영됨
- 대표적인 DDL -> SQL의 CREATE, ALTER, DROP
- CREATE -> 테이블,컬럼을 생성합니다.

- ALTER -> 테이블,컬럼을 변경합니다.
이미 만들어진 데이터베이스나 테이블 수정에 사용됩니다.
(한번에 하나의 명령만 실행가능합니다.)

- DROP -> 테이블,컬럼을 삭제합니다.

- RENAME -> 테이블,컬럼의 이름을 변경합니다.
RENAME TABLE old_table_name TO new_table_name;
- TRUNCATE -> 테이블의 모든 데이터를 빠르게 삭제합니다.
TRUNCATE TABLE table_name;
DML(Data Manipulation Language) - 데이터 조작 언어
- 데이터베이스에 저장된 데이터를 검색하거나 조작하는 언어
- DML을 질의어(query language)라고도 부름
- 데이터베이스 객체 안에 데이터를 삽입, 삭제, 수정, 조회 하는 명령어 포함함
- 대표적인 DML -> SQL의 SELECT, INSERT, UPDATE, DELETE
- SELECT -> 테이블에서 특정 컬럼(열) or 레코드(행)를 검색하는 명령어 입니다

- INSERT -> 테이블에서 새로운 데이터를 추가하는명령어 입니다. 데이터는 레코드 단위로 생성됩니다.

- UPDATE -> 테이블에서 레코드(행)의 값을 업데이트하는 명령어 입니다.

- DELETE -> 테이블에서 레코드를 삭제하는 명령어 입니다.

TRUNCATE vs DROP vs DELETE의 차이
DELETE - 테이블의 모든 데이터 삭제, but 디스크 사용량 초기화 X (UNDO 가능)
TRUNCATE - 테이블의 모든 데이터 삭제 및 디스크 사용량 초기화 (UNDO 불가능)
DROP - 테이블의 모든 데이터 삭제 및 디스크 사용량 초기화 + 테이블 스키마 정의 삭제 (UNDO 불가능)
DCL(Data Control Language) - 데이터 제어 언어
- 데이터베이스 접근권한을 제어하는 언어
- 각 사용자들의 접근권한을 변경할 수 있음.
- GRANT -> 사용자에게 특정 데이터베이스 객체에 대한 접근권한을 부여하는 명령어 입니다.
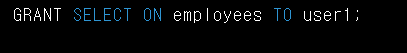
- REVOKE -> 사용자에게 특정 데이터베이스 객체에 대한 접근권한을 제거하는 명령어 입니다.

SELECT 문장 문법
SELECT a FROM R as r WHERE r.c=10 GROUP BY <~~~~> HAVING <~~~~> ORDER BY <~~~~>
SELECT
- 해당 테이블의 속성을 선택하여 명시함. (*일시 모든 속성 다가지고옴)
- 터플 중복을 허용함. (터플중복을 허용하지 않을시 distinct 조건 명시)
- 관계대수의 투영연산과 같음.
FROM
- 테이블을 명시, 여러개의 테이블도 가능.
- 테이블을 여러개 가져올시 관계대수의 카티시안곱과 같음.
- WHERE의 조건과함께 명시할시 조인연산도 가능
WHERE
- 터플이 만족하여야하는 조건 명시.
- 관계대수의 선택연산과 같음.
AS
- 테이블의 새 이름을 지정할 수 있음.
- 관계때수의 재명명연산과 같음
ORDER BY
- 명시된 조건을 통해 터플을 정렬할 수 있음.
- 기본값은 오름차순, desc는 내림차순.
집합 연산
- 집합연산은 여러개의 SELECT문의 결과 집합을 조합해 하나의 결과로 만드는 연산 이며, UNION , INTERSECT , EXCEPT가 있다.
UNION
- 여러개의 SELECT 문의 결과 집합의 중복을 제거하고 합치는 연산.
- SELECT문의 결과 속성값이 동일 해야함.
(SELECT column1, column2 FROM table1)
UNION
(SELECT column1 ,column2 FROM table2);
INTERSECT
- 여러 개의 SELECT 문의 결과 집합의 교집합을 구하는 연산.
- SELECT문의 결과 속성값이 동일 해야함.
(SELECT column1, column2 FROM table1)
INTERSECT
(SELECT column1, column2 FROM table2);
EXCEPT
- 첫번째 SELECT문의 결과에서 두번째 SELCET문의 결과를 차집합하는 연산.
- SELECT문의 결과 속성값이 동일 해야함.
(SELECT column1, column2 FROM table1)
EXCEPT
(SELECT column1, column2 FROM table2);
집합연산의 중복을 허용하고 싶을땐 연산자 뒤에 ALL연산자를 붙이면 됩니다.
'DB' 카테고리의 다른 글
| 데이터베이스 뷰(VIEW) (0) | 2023.05.03 |
|---|---|
| SELECT 기본구조 (0) | 2023.04.21 |
| 추가 관계 대수 (0) | 2023.03.27 |
| 기본 관계 대수 (0) | 2023.03.27 |
| 관계형 데이터베이스 제약조건 (Constraint) (0) | 2023.03.26 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- sql
- 클라우드
- 보안
- 네트워크
- 컴퓨터구조
- 서버
- nat
- 웹소켓
- 포트포워딩
- 스프링
- 메세지큐
- 데이터베이스
- 깃
- 도커
- 인공지능
- 깃허브
- 테이블
- 문법
- JPA
- 프로토콜
- 데이터
- 소프트웨어공학
- 자동화
- IP주소
- 자바
- 쿼리
- 배포
- 파인튜닝
- DB
- 컨테이너
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
글 보관함